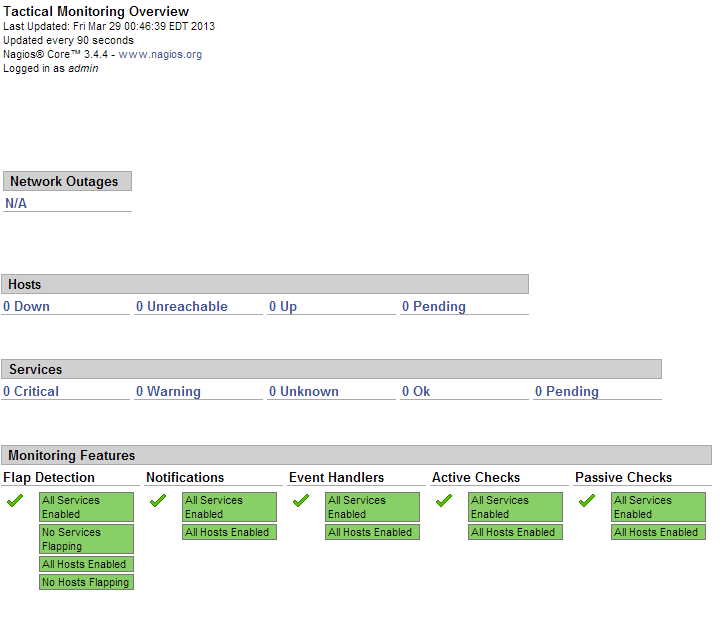
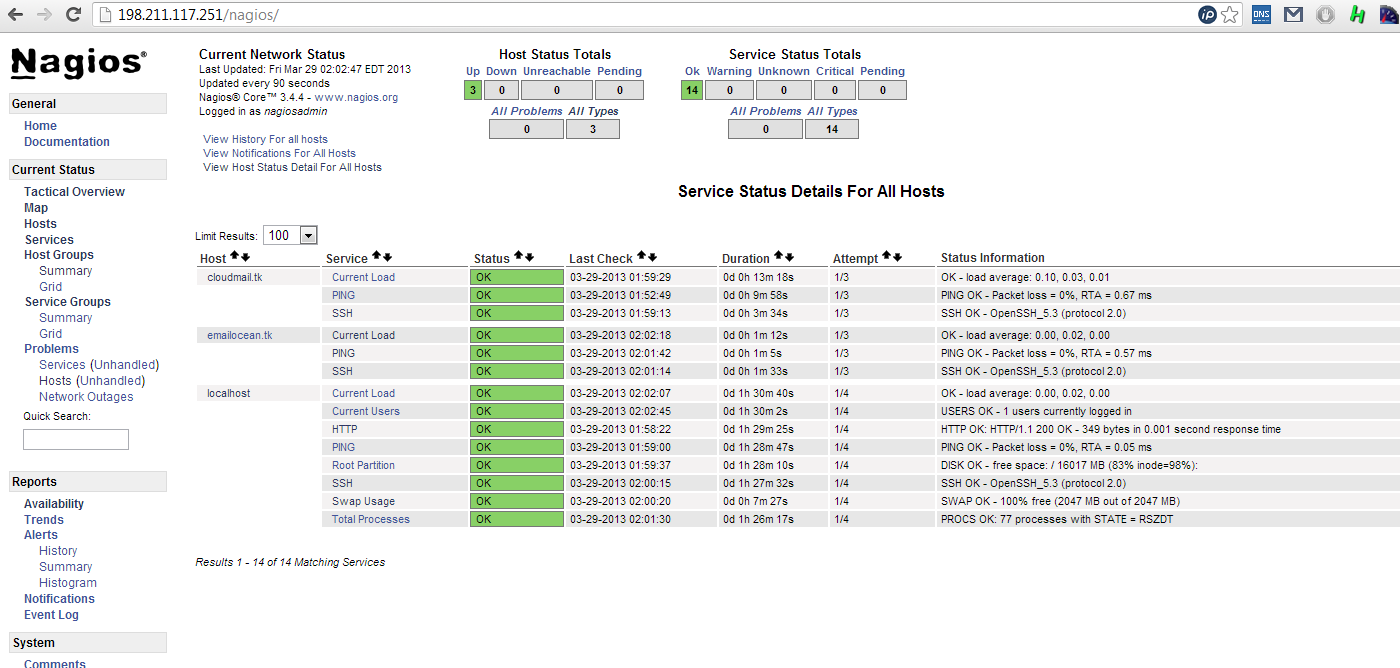
I assume that you already have
VirtualBox and
Vagrant installed...
Set up
On guest machine, create a folder that would contain files for the VM
mkdir hadoop_ambari
Change to it and issue command to download the VM box and to add it to your library of VMs with specific name.
cd hadoop_ambari
vagrant box add hadoop_ambari https://github.com/2creatives/vagrant-centos/releases/download/v6.5.1/centos65-x86_64-20131205.box
Once download is complete, we can initialize Vagrant, which in turn would create Vagrantfile that acts as a configuration file. Various options are available to be specified: memory, ip, ports, etc.
vagrant init hadoop_ambari
Open Vagrantfile with vi editor and make following changes
config.vm.network :forwarded_port, guest: 8080, host: 8080
config.vm.network "private_network", ip: "192.168.33.10"
config.vm.provider "virtualbox" do |vb| #
# Use VBoxManage to customize the VM. For example to change memory:
vb.customize ["modifyvm", :id, "--memory", "8192"]
end
Here we assigned static ip, opened port 8080 and made sure that we have 8GB of memory allocated to the machine.
Save the file and start vagrant
vagrant up
Once it starts, log in and change to root
vagrant ssh
inside of guest OS
sudo su
cd ~
Find out hostname of the machine
hostname
Edit /etc/hosts file to the following
vi /etc/hosts
192.168.33.11 <hostname>
(this ip was specified as static inside of your Vagrant file)
Install NTP service
yum install ntp
Install wget Utility
yum install wget
Turn on NTP service
chkconfig ntpd on
service ntpd start
Set up passwordless SSH
ssh-keygen
cd .ssh
cp id_rsa /vagrant
cat id_rsa.pub >> authorized_keys
Setup Ambari
wget http://public-repo-1.hortonworks.com/ambari/centos6/1.x/updates/1.4.3.38/ambari.repo
cp ambari.repo /etc/yum.repos.d
Double check that repo was created
yum repolist
Install Ambari server
yum install ambari-server
Configure it (go with defaults)
ambari-server setup
Start Ambari Server
ambari-server start
Wait a little and you should be able to access your server at
http://192.168.33.11:8080. Username and password: ambari/ambari. Follow the wizard which is self explanatory. In Install Options specify hostname of guest machine and then provide ssh private key by navigating to the hadoop_ambari folder that contains your Vagrantfile and id_rsa (remember when you copied your id_rsa file in guest OS to /vagrant folder?). In Customize Services, pick passwords for the services.
Wait for the installation to finish and enjoy your new set up! When browsing URLs inside of ambari, it by default would try to link to hostname and that won't work, so use the static ip instead. For example, MR2 JobHistory UI would be on
http://192.168.33.11:19888.
Like always, comments? questions? just post!
Troubleshooting:
1.
If you can not get to the URLs, try to disable iptables
service iptables stop
Verify that curl is able to access the apache test page from inside the vm
vagrant ssh
curl -v localhost
If that doesn't work, then it's definitely not the port forwarding.
Lastly verify that the Host can access the page through curl
curl -v 'http://localhost:8080'
2.
Check if server is listening on 8080 and where it is binding
netstat -ntlp | grep 8080
Note that 127.0.0.1 is only accessible to the local machine, which for a guest machine means nothing. Outside of the VM, it can't reach it! 0.0.0.0 is accessible from anywhere on the local network, which to a VM includes the host machine.
127.0.0.1 is normally the IP address assigned to the "loopback" or local-only interface. This is a "fake" network adapter that can only communicate within the same host. It's often used when you want a network-capable application to only serve clients on the same host. A process that is listening on 127.0.0.1 for connections will only receive local connections on that socket.
"localhost" is normally the hostname for the 127.0.0.1 IP address. It's usually set in /etc/hosts (or the Windows equivalent named "hosts" somewhere under %WINDIR%). You can use it just like any other hostname - try "ping localhost" to see how it resolves to 127.0.0.1.
0.0.0.0 has a couple of different meanings, but in this context, when a server is told to listen on 0.0.0.0 that means "listen on every available network interface". The loopback adapter with IP address 127.0.0.1 from the perspective of the server process looks just like any other network adapter on the machine, so a server told to listen on 0.0.0.0 will accept connections on that interface too.
Resources:
List of ports
config.vm.network :forwarded_port, guest: 80, host: 42080, auto_correct: true #Apache http
config.vm.network :forwarded_port, guest: 111, host: 42111, auto_correct: true #NFS portmap
config.vm.network :forwarded_port, guest: 2223, host: 2223, auto_correct: true #Gateway node
config.vm.network :forwarded_port, guest: 8000, host: 8000, auto_correct: true #Hue
config.vm.network :forwarded_port, guest: 8020, host: 8020, auto_correct: true #Hdfs
config.vm.network :forwarded_port, guest: 8042, host: 8042, auto_correct: true #NodeManager
config.vm.network :forwarded_port, guest: 8050, host: 8050, auto_correct: true #Resource manager
config.vm.network :forwarded_port, guest: 8080, host: 8080, auto_correct: true #Ambari
config.vm.network :forwarded_port, guest: 8088, host: 8088, auto_correct: true #Yarn RM
config.vm.network :forwarded_port, guest: 8443, host: 8443, auto_correct: true #Knox gateway
config.vm.network :forwarded_port, guest: 8744, host: 8744, auto_correct: true #Storm UI
config.vm.network :forwarded_port, guest: 8888, host: 8888, auto_correct: true #Tutorials
config.vm.network :forwarded_port, guest: 10000, host: 10000, auto_correct: true #HiveServer2 thrift
config.vm.network :forwarded_port, guest: 10001, host: 10001, auto_correct: true #HiveServer2 thrift http
config.vm.network :forwarded_port, guest: 11000, host: 11000, auto_correct: true #Oozie
config.vm.network :forwarded_port, guest: 15000, host: 15000, auto_correct: true #Falcon
config.vm.network :forwarded_port, guest: 19888, host: 19888, auto_correct: true #Job history
config.vm.network :forwarded_port, guest: 50070, host: 50070, auto_correct: true #WebHdfs
config.vm.network :forwarded_port, guest: 50075, host: 50075, auto_correct: true #Datanode
config.vm.network :forwarded_port, guest: 50111, host: 50111, auto_correct: true #WebHcat
config.vm.network :forwarded_port, guest: 60080, host: 60080, auto_correct: true #WebHBase
References:
https://github.com/petro-rudenko/bigdata-toolbox/blob/master/Vagrantfile
http://serverfault.com/questions/513654/troubleshooting-why-1-vagrant-works-but-another-does-not
http://stackoverflow.com/questions/5984217/vagrants-port-forwarding-not-working
http://stackoverflow.com/questions/23840098/empty-reply-from-server-cant-connect-to-vagrant-vm-w-port-forwarding
http://stackoverflow.com/questions/20778771/what-is-the-difference-between-0-0-0-0-127-0-0-1-and-localhost